Выборки и доверительные интервалы. Доверительный интервал
Ум заключается не только в знании, но и в умении прилагать знание на деле. (Аристотель)
Доверительные интервалы
Общий обзор
Взяв выборку из популяции, мы получим точечную оценку интересующего нас параметра и вычислим стандартную ошибку для того, чтобы указать точность оценки.
Однако, для большинства случаев стандартная ошибка как такова не приемлема. Гораздо полезнее объединить эту меру точности с интервальной оценкой для параметра популяции.
Это можно сделать, используя знания о теоретическом распределении вероятности выборочной статистики (параметра) для того, чтобы вычислить доверительный интервал (CI - Confidence Interval, ДИ - Доверительный интервал) для параметра.
Вообще, доверительный интервал расширяет оценки в обе стороны некоторой величиной, кратной стандартной ошибке (данного параметра); два значения (доверительные границы), определяющие интервал, обычно отделяют запятой и заключают в скобки.
Доверительный интервал для среднего
Использование нормального распределения
Выборочное среднее имеет нормальное распределение, если объем выборки большой, поэтому можно применить знания о нормальном распределении при рассмотрении выборочного среднего.
В частности, 95% распределения выборочных средних находится в пределах 1,96 стандартных отклонений (SD) среднего популяции.
Когда у нас есть только одна выборка, мы называем это стандартной ошибкой среднего (SEM) и вычисляем 95% доверительного интервала для среднего следующим образом:
Если повторить этот эксперимент несколько раз, то интервал будет содержать истинное среднее популяции в 95% случаев.
Обычно это доверительный интервал как, например, интервал значений, в пределах которого с доверительной вероятностью 95% находится истинное среднее популяции (генеральное среднее).
Хотя это не вполне строго (среднее в популяции есть фиксированное значение и поэтому не может иметь вероятность, отнесённую к нему) таким образом интерпретировать доверительный интервал, но концептуально это удобнее для понимания.
Использование t- распределения
Можно использовать нормальное распределение, если знать значение дисперсии в популяции. Кроме того, когда объем выборки небольшой, выборочное среднее отвечает нормальному распределению, если данные, лежащие в основе популяции, распределены нормально.
Если данные, лежащие в основе популяции, распределены ненормально и/или неизвестна генеральная дисперсия (дисперсия в популяции), выборочное среднее подчиняется t-распределению Стьюдента
.
Вычисляем 95% доверительный интервал для генерального среднего в популяции следующим образом:
Где - процентная точка (процентиль) t- распределения Стьюдента с (n-1) степенями свободы, которая даёт двухстороннюю вероятность 0,05.
Вообще, она обеспечивает более широкий интервал, чем при использовании нормального распределения, поскольку учитывает дополнительную неопределенность, которую вводят, оценивая стандартное отклонение популяции и/или из-за небольшого объёма выборки.
Когда объём выборки большой (порядка 100 и более), разница между двумя распределениями (t-Стьюдента и нормальным) незначительна. Тем не менее всегда используют t- распределение при вычислении доверительных интервалов, даже если объем выборки большой.
Обычно указывают 95% ДИ. Можно вычислить другие доверительные интервалы, например 99% ДИ для среднего.
Вместо произведения стандартной ошибки и табличного значения t- распределения, которое соответствует двусторонней вероятности 0,05, умножают её (стандартную ошибку) на значение, которое соответствует двусторонней вероятности 0,01. Это более широкий доверительный интервал, чем в случае 95%, поскольку он отражает увеличенное доверие к тому, что интервал действительно включает среднее популяции.
Доверительный интервал для пропорции
Выборочное распределение пропорций имеет биномиальное распределение. Однако если объём выборки n
разумно большой, тогда выборочное распределение пропорции приблизительно нормально со средним .
Оцениваем выборочным отношением p=r/n (где r - количество индивидуумов в выборке с интересующими нас характерными особенностями), и стандартная ошибка оценивается:
95% доверительный интервал для пропорции оценивается:

Если объём выборки небольшой (обычно когда np
или n(1-p)
меньше 5
), тогда необходимо использовать биномиальное распределение для того, чтобы вычислить точные доверительные интервалы.
Заметьте, что если p выражается в процентах, то (1-p) заменяют на (100-p) .
Интерпретация доверительных интервалов
При интерпретации доверительного интервала нас интересуют следующие вопросы:
Насколько широк доверительный интервал?
Широкий доверительный интервал указывает на то, что оценка неточна; узкий указывает на точную оценку.
Ширина доверительного интервала зависит от размера стандартной ошибки, которая, в свою очередь, зависит от объёма выборки и при рассмотрении числовой переменной от изменчивости данных дают более широкие доверительные интервалы, чем исследования многочисленного набора данных немногих переменных.
Включает ли ДИ какие-либо значения, представляющие особенный интерес?
Можно проверить, ложится ли вероятное значение для параметра популяции в пределы доверительного интервала. Если да, то результаты согласуются с этим вероятным значением. Если нет, тогда маловероятно (для 95% доверительного интервала шанс почти 5%), что параметр имеет это значение.
Доверительный интервал пришел к нам из области статистики. Это определенный диапазон, который служит для оценки неизвестного параметра с высокой степенью надежности. Проще всего это будет пояснить на примере.
Предположим, нужно исследовать какую-либо случайную величину, например, скорость отклика сервера на запрос клиента. Каждый раз, когда пользователь набирает адрес конкретного сайта, сервер реагирует на это с разной скоростью. Таким образом, исследуемое время отклика имеет случайный характер. Так вот, доверительный интервал позволяет определить границы этого параметра, и затем можно будет утверждать, что с вероятностью в 95% сервера будет находиться в рассчитанном нами диапазоне.
Или же нужно узнать, какому количеству людей известно о торговой марке фирмы. Когда будет подсчитан доверительный интервал, то можно будет, к примеру, сказать что с 95% долей вероятности доля потребителей, знающих о данной находится в диапазоне от 27% до 34%.
С этим термином тесно связана такая величина, как доверительная вероятность. Она представляет собой вероятность того, что искомый параметр входит в доверительный интервал. От этой величины зависит то, насколько большим окажется наш искомый диапазон. Чем большее значение она принимает, тем уже становится доверительный интервал, и наоборот. Обычно ее устанавливают равной 90%, 95% или 99%. Величина 95% наиболее популярна.
На данный показатель также оказывает влияние дисперсия наблюдений и Его определение основано на том предположении, что исследуемый признак подчиняется Это утверждение известно также как Закон Гаусса. Согласно ему, нормальным называется такое распределение всех вероятностей непрерывной случайной величины, которое можно описать плотностью вероятностей. Если предположение о нормальном распределении оказалось ошибочным, то оценка может оказаться неверной.
Сначала разберемся с тем, как вычислить доверительный интервал для Здесь возможны два случая. Дисперсия (степень разброса случайной величины) может быть известна либо нет. Если она известна, то наш доверительный интервал вычисляется с помощью следующей формулы:
хср - t*σ / (sqrt(n)) <= α <= хср + t*σ / (sqrt(n)), где
α - признак,
t - параметр из таблицы распределения Лапласа,
σ - квадратный корень дисперсии.
Если дисперсия неизвестна, то ее можно рассчитать, если нам известны все значения искомого признака. Для этого используется следующая формула:
σ2 = х2ср - (хср)2, где
х2ср - среднее значение квадратов исследуемого признака,
(хср)2 - квадрат данного признака.
Формула, по которой в этом случае рассчитывается доверительный интервал немного меняется:
хср - t*s / (sqrt(n)) <= α <= хср + t*s / (sqrt(n)), где
хср - выборочное среднее,
α - признак,
t - параметр, который находят с помощью таблицы распределения Стьюдента t = t(ɣ;n-1),
sqrt(n) - квадратный корень общего объема выборки,
s - квадратный корень дисперсии.
Рассмотри такой пример. Предположим, что по результатам 7 замеров была определена исследуемого признака, равная 30 и дисперсия выборки, равная 36. Нужно найти с вероятностью в 99% доверительный интервал, который содержит истинное значение измеряемого параметра.
Вначале определим чему равно t: t = t (0,99; 7-1) = 3.71. Используем приведенную выше формулу, получаем:
хср - t*s / (sqrt(n)) <= α <= хср + t*s / (sqrt(n))
30 - 3.71*36 / (sqrt(7)) <= α <= 30 + 3.71*36 / (sqrt(7))
21.587 <= α <= 38.413
Доверительный интервал для дисперсии рассчитывается как в случае с известным средним, так и тогда, когда нет никаких данных о математическом ожидании, а известно лишь значение точечной несмещенной оценки дисперсии. Мы не будем приводить здесь формулы его расчета, так как они довольно сложные и при желании их всегда можно найти в сети.
Отметим лишь, что доверительный интервал удобно определять с помощью программы Excel или сетевого сервиса, который так и называется.
Из данной статьи вы узнаете:
Что такое доверительный интервал ?
В чем суть правила 3-х сигм ?
Как можно применить эти знания на практике?
В наше время из-за переизбытка информации, связанного с большим ассортиментом товаров, направлений продаж, сотрудников, направлений деятельности и т.д., бывает трудно выделить главное , на что, в первую очередь, стоит обратить внимание и приложить усилия для управления. Определение доверительного интервала и анализ выхода за его границы фактических значений - методика, которая поможет вам выделить ситуации , влияющие на изменение тенденций. Вы сможете развивать позитивные факторы и снизить влияние негативных. Данная технология применяется во многих известных мировых компаниях.
Существуют так называемые "оповещения" , которые информируют руководителей о том, что очередное значение в определенном направлении вышло за доверительный интервал . Что это означает? Это сигнал, что произошло какое-то нестандартное событие, которое, возможно, изменит существующую тенденцию в данном направлении. Это сигнал к тому, чтобы разобраться в ситуации и понять, что на неё повлияло.
Например, рассмотрим несколько ситуаций. Мы рассчитали прогноз продаж с границами прогноза по 100 товарным позициям на 2011 год по месяцам и в марте фактические продажи:
- По «Подсолнечному маслу» пробили верхнюю границу прогноза и не попали в доверительный интервал.
- По «Сухим дрожжам» вышли за нижнюю границу прогноза.
- По «Овсяным Кашам» пробили верхнюю границу.
По остальным товарам фактические продажи оказались в рамках заданных границ прогноза. Т.е. их продажи оказались в рамках ожиданий. Итак, мы выделили 3 товара, которые вышли за границы, и начали разбираться, что же повлияло на выход за границы:
- По «Подсолнечному маслу» мы вошли в новую торговую сеть, которая дала нам дополнительный объем продаж, что привело к выходу за верхнюю границу. Для этого товара стоит пересчитать прогноз до конца года с учетом прогноза продаж в данную сеть.
- По «Сухим дрожжам» машина застряла на таможне, и образовался дефицит в рамках 5 дней, что повлияло на снижение продаж и выход за нижнюю границу. Возможно, стоит разобраться, что послужило причиной и постараться не повторять данную ситуацию.
- По «Овсяным Кашам» было запущено мероприятие по стимулированию сбыта, которое дало значительный прирост продаж и привело к выходу за границы прогноза.
Мы выделили 3 фактора, которые повлияли на выход за границы прогноза. В жизни их может быть гораздо больше.Для повышения точности прогнозирования и планирования факторы, которые приводят к тому, что фактические продажи могут выйти за границы прогноза, стоит выделить и строить прогнозы и планы по ним отдельно. А затем учитывать их влияние на основной прогноз продаж. Также можно регулярно оценивать влияние данных факторов и менять ситуацию к лучшему за счет уменьшения влияния негативных и увеличения влияния позитивных факторов .
С помощью доверительного интервала мы можем:
- Выделить направления , на которые стоит обратить внимание, т.к. в этих направлениях произошли события, которые могут повлиять на изменение тенденции .
- Определить факторы , которые реально влияют на изменение ситуации.
- Принять взвешенное решение (например, о закупках, при планировании и т.д.).
Теперь рассмотрим, что такое доверительный интервал и как его рассчитать в Excel на примере.
Что такое доверительный интервал?
Доверительный интервал – это границы прогноза (верхняя и нижняя), в рамки которых с заданной вероятностью (сигма) попадут фактические значения.
Т.е. мы рассчитываем прогноз - это наш основной ориентир, но мы понимаем, что фактические значения вряд ли на 100% будут равны нашему прогнозу. И возникает вопрос, в какие границы могут попасть фактические значения, если существующая тенденция сохранится ? И на этот вопрос нам поможет ответить расчет доверительного интервала , т.е. - верхней и нижней границы прогноза.
Что такое заданная вероятность сигма?
При расчете доверительного интервала мы можем задать вероятность попадания фактических значений в заданные границы прогноза . Как это сделать? Для этого мы задаем значение сигма и, если сигма будет равна:
3 сигма - то, вероятность попадания очередного фактического значения в доверительный интервал составят 99,7%, или 300 к 1, или существует 0,3% вероятности выхода за границы.
2 сигма - то, вероятность попадания очередного значения в границы составляет ≈ 95,5 %, т.е. шансы примерно 20 к 1, или существует 4,5% вероятности выхода за границы.
1 сигма - то, вероятность ≈ 68,3%, т.е. шансы примерно 2 к 1, или существует 31,7% вероятность того, что очередное значение выйдет за пределы доверительного интервала.
Мы сформулировали правило 3 сигм, которое гласит, что вероятность попадания очередного случайного значения в доверительный интервал с заданным значением три сигма составляет 99.7% .
Великим русским математиком Чебышевым была доказана теорема о том, что существует 10% вероятность выхода за границы прогноза с заданным значением три сигма. Т.е. вероятность попадания в доверительный интервал 3 сигма составит минимум 90%, в то время как попытка рассчитать прогноз и его границы «на глазок» чревата куда более существенными ошибками.
Как самостоятельно рассчитать доверительный интервал в Excel?
Расчет доверительного интервала в Excel (т.е. верхней и нижней границы прогноза) рассмотрим на примере. У нас есть временной ряд - продажи по месяцам за 5 лет. См. Вложенный файл.
Для расчета границ прогноза рассчитаем:
- Прогноз продаж ().
- Сигма - среднеквадратическое отклонение модели прогноза от фактических значений.
- Три сигма.
- Доверительный интервал.
1. Прогноз продаж.
=(RC[-14](данные во временном ряду) - RC[-1](значение модели) )^2(в квадрате)

3. Просуммируем для каждого месяца значения отклонений из 8 этапа Сумма((Xi-Ximod)^2), т.е. просуммируем январи, феврали... для каждого года.
Для этого воспользуемся формулой =СУММЕСЛИ()
СУММЕСЛИ(массив с номерами периодов внутри цикла (для месяцев от 1 до 12);ссылка на номер периода в цикле; ссылка на массив с квадратами разницы исходных данных и значений периодов)

4. Рассчитаем среднеквадратическое отклонение для каждого периода в цикле от 1 до 12 (10 этапво вложенном файле ).
Для этого из значения рассчитанного на 9 этапе мы извлекаем корень и делим на количество периодов в этом цикле минус 1 = КОРЕНЬ((Сумма(Xi-Ximod)^2/(n-1))
Воспользуемся формулами в Excel =КОРЕНЬ(R8 (ссылка на (Сумма(Xi-Ximod)^2) /(СЧЁТЕСЛИ($O$8:$O$67 (ссылка на массив с номерами цикла) ; O8 (ссылка на конкретный номер цикла, которые считаем в массиве) )-1))
С помощью формулы Excel = СЧЁТЕСЛИ мы считаем количество n

Рассчитав среднеквадратическое отклонение фактических данных от модели прогноза, мы получили значение сигма для каждого месяца - этап 10 во вложенном файле .
3. Рассчитаем 3 сигма.
На 11 этапе задаем количество сигм - в нашем примере «3» (11 этапво вложенном файле ):

Также удобные для практики значения сигма:
1,64 сигма - 10% вероятность выхода за предел (1 шанс из 10);
1,96 сигма - 5% вероятность выхода за пределы (1 шанс из 20);
2,6 сигма - 1% вероятность выхода за пределы (1 шанс из 100).
5) Рассчитываем три сигма , для этого мы значения «сигма» для каждого месяца умножаем на «3».

3.Определяем доверительный интервал.
- Верхняя граница прогноза - прогноз продаж с учетом роста и сезонности + (плюс) 3 сигма;
- Нижняя граница прогноза - прогноз продаж с учетом роста и сезонности – (минус) 3 сигма;
Для удобства расчета доверительного интервала на длительный период (см. вложенный файл) воспользуемся формулой Excel =Y8+ВПР(W8;$U$8:$V$19;2;0) , где
Y8 - прогноз продаж;
W8 - номер месяца, для которого будем брать значение 3-х сигма;
Т.е. Верхняя граница прогноза = «прогноз продаж» + «3 сигма» (в примере, ВПР(номер месяца; таблица со значениями 3-х сигма; столбец, из которого извлекаем значение сигма равное номеру месяца в соответствующей строке;0)).

Нижняя граница прогноза = «прогноз продаж» минус «3 сигма».
Итак, мы рассчитали доверительный интервал в Excel.
Теперь у нас есть прогноз и диапазон с границами в пределах, которого с заданной вероятностью сигма попадут фактические значения.
В данной статье мы рассмотрели, что такое сигма и правило трёх сигм, как определить доверительный интервал и для чего вы можете использовать данную методику на практике.
Точных вам прогнозов и успехов!
Чем Forecast4AC PRO может вам помочь при расчете доверительного интервала ?:
Forecast4AC PRO автоматически рассчитает верхнюю или нижнюю границы прогноза для более чем 1000 временных рядов одновременно;
Возможность анализа границ прогноза в сравнении с прогнозом, трендом и фактическими продажами на графике одним нажатием клавиши;
В программе Forcast4AC PRO есть возможность задать значение сигма от 1 до 3.
Присоединяйтесь к нам!
Скачивайте бесплатные приложения для прогнозирования и бизнес-анализа :

- Novo Forecast Lite - автоматический расчет прогноза в Excel .
- 4analytics - ABC-XYZ-анализ и анализ выбросов в Excel.
- Qlik Sense Desktop и QlikView Personal Edition - BI-системы для анализа и визуализации данных.
Тестируйте возможности платных решений:
- Novo Forecast PRO - прогнозирование в Excel для больших массивов данных.
Пусть у нас имеется большое количество предметов, с нормальным распределением некоторых характеристик (например, полный склад однотипных овощей, размер и вес которых варьируется). Вы хотите знать средние характеристики всей партии товара, но у Вас нет ни времени, ни желания измерять и взвешивать каждый овощ. Вы понимаете, что в этом нет необходимости. Но сколько штук надо было бы взять на выборочную проверку?
Прежде, чем дать несколько полезных для этой ситуации формул напомним некоторые обозначения.
Во-первых, если бы мы все-таки промерили весь склад овощей (эт о множество элементов называется генеральной совокупностью), то мы узнали бы со всей доступной нам точностью среднее значение веса всей партии. Назовем это среднее значение Х ср.г ен . - генеральным средним. Мы уже знаем, что определяется полностью, если известно его среднее значение и отклонение s . Правда, пока мы ни Х ср.ген., ни s генеральной совокупности не знаем. Мы можем только взять некоторую выборку, замерить нужные нам значения и посчитать для этой выборки как среднее значение Х ср.в ыб., так и среднее квадратическое отклонение S выб.
Известно, что если наша выборочная проверка содержит большое количество элементов (обычно n больше 30), и они взяты действительно случайным образом , то s генеральной совокупности почти не будет отличаться от S выб ..
Кроме того, для случая нормального распределения мы можем пользоваться следующими формулами:
С вероятностью 95%
С вероятностью 99%
![]()
В общем виде c вероятностью Р
(t)
Связь значения t со значением вероятности Р
(t), с
которой мы хотим знать доверительный интервал, можно взять из следующей таблицы:
Таким образом, мы определили, в каком диапазоне находится среднее значение
для генеральной совокупности (с данной вероятностью).
Если у нас нет достаточно большой выборки, мы не можем утверждать, что генеральная совокупность имеет s = S выб. Кроме того, в этом случае проблематична близость выборки к нормальному распределению. В этом случае также пользуются S выб вместо s в формуле:

но значение t для фиксированной вероятности Р
(t)
будет зависеть от количества элементов в выборке n. Чем больше n, тем ближе
будет полученный доверительный интервал к значению, даваемому формулой (1).
Значения t в этом случае берутся из другой таблицы (t-критерий Стьюдента),
которую мы приводим ниже:
Значения t-критерия Стьюдента для
вероятности 0,95 и 0,99

Пример 3.
Из
работников фирмы случайным образом отобрано 30 человек. По выборке оказалось,
что средняя зарплата (в месяц) составляет 30 тыс. рублей при среднем
квадратическом отклонении 5 тыс. рублей. С вероятностью 0,99 определить
среднюю зарплату в фирме.
Решение: По условию имеем n = 30, Х ср. =30000, S=5000, Р = 0,99. Для нахождения доверительного интервала воспользуемся формулой, соответствующей критерию Стьюдента. По таблице для n = 30 и Р = 0,99 находим t=2,756, следовательно,
т.е. искомый доверительный
интервал 27484 < Х ср.ген
< 32516.
Итак, вероятностью 0,99 можно утверждать, что интервал (27484; 32516) содержит внутри себя среднюю зарплату в фирме.
Мы надеемся, что Вы будете пользоваться этим методом, при этом не обязательно, чтобы при Вас каждый раз была таблица. Подсчеты можно проводить в Excel автоматически. Находясь в файле Excel, нажмите в верхнем меню кнопку fx. Затем, выберите среди функций тип "статистические", и из предложенного перечня в окошке - СТЬЮДРАСПОБР. Затем, по подсказке, поставив курсор в поле "вероятность" наберите значение обратной вероятности (т.е. в нашем случае вместо вероятности 0,95 надо набирать вероятность 0,05). Видимо, электронная таблица составлена так, что результат отвечает на вопрос, с какой вероятностью мы можем ошибиться. Аналогично в поле "степень свободы" введите значение (n-1) для своей выборки.
Цель – научить студентов алгоритмам вычисления доверительных интервалов статистических параметров.
При статистической обработке данных вычисленные средняя арифметическая, коэффициент вариации, коэффициент корреляции, критерии различия и другие точечные статистики должны получить количественные границы доверия, которые обозначают возможные колебания показателя в меньшую и большую стороны в пределах доверительного интервала.
Пример
3.1
.
Распределение
кальция в сыворотке крови обезьян, как
было установлено ранее, характеризуется
следующими выборочными показателями:
=
11,94 мг%; =
0,127 мг%;n
= 100. Требуется определить доверительный
интервал для генеральной средней (
=
0,127 мг%;n
= 100. Требуется определить доверительный
интервал для генеральной средней ( )
при доверительной вероятностиP
= 0,95.
)
при доверительной вероятностиP
= 0,95.
Генеральная средняя находится с определенной вероятностью в интервале:
 ,
где
,
где
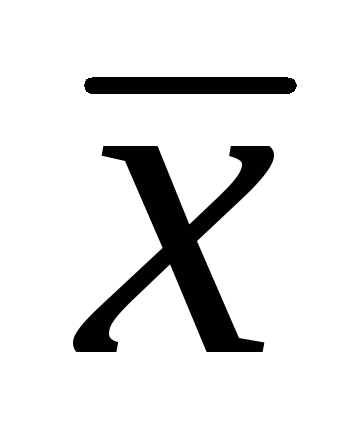 –
выборочная средняя арифметическая;t
– критерий Стьюдента;
–
выборочная средняя арифметическая;t
– критерий Стьюдента;
 –
ошибка средней арифметической.
–
ошибка средней арифметической.
По
таблице «Значения критерия Стьюдента»
находим значение
 при доверительной вероятности 0,95 и
числе степеней свободы k
= 100-1 = 99. Оно равно 1,982. Вместе со значениями
среднего арифметического и статистической
ошибки подставляем его в формулу:
при доверительной вероятности 0,95 и
числе степеней свободы k
= 100-1 = 99. Оно равно 1,982. Вместе со значениями
среднего арифметического и статистической
ошибки подставляем его в формулу:
или
11,69
 12,19
12,19
Таким образом, с вероятностью 95%, можно утверждать, что генеральная средняя данного нормального распределения находится между 11,69 и 12,19 мг%.
Пример
3.2
. Определите
границы 95%-ного доверительного интервала
для генеральной дисперсии ( )
распределения кальция в крови обезьян,
если известно, что
)
распределения кальция в крови обезьян,
если известно, что =
1,60, приn
= 100.
=
1,60, приn
= 100.
Для решения задачи можно воспользоваться следующей формулой:
Где
 –
статистическая ошибка дисперсии.
–
статистическая ошибка дисперсии.
Находим
ошибку выборочной дисперсии по формуле:
 .
Она равна 0,11. Значениеt
-
критерия при доверительной вероятности
0,95 и числе степеней свободы k
= 100–1 = 99 известно из предыдущего примера.
.
Она равна 0,11. Значениеt
-
критерия при доверительной вероятности
0,95 и числе степеней свободы k
= 100–1 = 99 известно из предыдущего примера.
Воспользуемся формулой и получим:
или
1,38
 1,82
1,82
Более
точно доверительный интервал генеральной
дисперсии можно построить с применением
 (хи-квадрат)
- критерия Пирсона. Критические точки
для этого критерия приводятся в
специальной таблице. При использовании
критерия
(хи-квадрат)
- критерия Пирсона. Критические точки
для этого критерия приводятся в
специальной таблице. При использовании
критерия для
построения доверительного интервала
применяют двусторонний уровень
значимости. Для нижней границы уровень
значимости рассчитывается по формуле
для
построения доверительного интервала
применяют двусторонний уровень
значимости. Для нижней границы уровень
значимости рассчитывается по формуле ,
для верхней –
,
для верхней – .
Например, для доверительного уровня
.
Например, для доверительного уровня =
0,99
=
0,99 = 0,010,
= 0,010, =
0,990. Соответственно по таблице распределения
критических значений
=
0,990. Соответственно по таблице распределения
критических значений ,
при рассчитанных доверительных уровнях
и числе степеней свободыk
= 100 – 1= 99, найдем значения
,
при рассчитанных доверительных уровнях
и числе степеней свободыk
= 100 – 1= 99, найдем значения
 и
и .
Получаем
.
Получаем равно 135,80, а
равно 135,80, а равно70,06.
равно70,06.
Чтобы
найти доверительные границы генеральной
дисперсии с помощью
 воспользуемся
формулами: для нижней границы
воспользуемся
формулами: для нижней границы ,
для верхней границы
,
для верхней границы .
Подставим данные задачи найденные
значения
.
Подставим данные задачи найденные
значения в
формулы:
в
формулы: =
1,17;
=
1,17; =
2,26. Таким образом, при доверительной
вероятностиP
= 0,99 или 99% генеральная дисперсия будет
лежать в интервале от 1,17 до 2,26 мг%
включительно.
=
2,26. Таким образом, при доверительной
вероятностиP
= 0,99 или 99% генеральная дисперсия будет
лежать в интервале от 1,17 до 2,26 мг%
включительно.
Пример 3.3 . Среди 1000 семян пшеницы из поступившей на элеватор партии обнаружено 120 семян зараженных спорыньей. Необходимо определить вероятные границы генеральной доли зараженных семян в данной партии пшеницы.
Доверительные границы для генеральной доли при всех возможных ее значениях целесообразно определять по формуле:
 ,
,
Где n – число наблюдений; m – абсолютная численность одной из групп; t – нормированное отклонение.
Выборочная
доля зараженных семян равна
 или 12%. При доверительной вероятностиР
= 95% нормированное отклонение (t
-критерий
Стьюдента при k
=
или 12%. При доверительной вероятностиР
= 95% нормированное отклонение (t
-критерий
Стьюдента при k
=
 )t
= 1,960.
)t
= 1,960.
Подставляем имеющиеся данные в формулу:
Отсюда
границы доверительного интервала
равны =
0,122–0,041 = 0,081, или 8,1%;
=
0,122–0,041 = 0,081, или 8,1%; = 0,122 + 0,041 = 0,163, или 16,3%.
= 0,122 + 0,041 = 0,163, или 16,3%.
Таким образом, с доверительной вероятностью 95% можно утверждать, что генеральная доля зараженных семян находится между 8,1 и 16,3%.
Пример 3.4 . Коэффициент вариации, характеризующий варьирование кальция (мг%) в сыворотке крови обезьян, оказался равным 10,6%. Объем выборки n = 100. Необходимо определить границы 95%-ного доверительного интервала для генерального параметра Cv .
Границы доверительного интервала для генерального коэффициента вариации Cv определяются по следующим формулам:
 и
и
 ,
гдеK
промежуточная
величина, вычисляемая по формуле
,
гдеK
промежуточная
величина, вычисляемая по формуле
 .
.
Зная,
что при доверительной вероятности Р
= 95% нормированное отклонение (критерий
Стьюдента при k
=
 )t
= 1,960,
предварительно рассчитаем величину К:
)t
= 1,960,
предварительно рассчитаем величину К:
 .
.
 или
9,3%
или
9,3%
 или
12,3%
или
12,3%
Таким образом, генеральный коэффициент вариации с доверительной вероятностью 95% лежит в интервале от 9,3 до 12,3%. При повторных выборках коэффициент вариации не превысит 12,3% и не окажется ниже 9,3% в 95 случаях из 100.
Вопросы для самоконтроля:

Задачи для самостоятельного решения.
1. Средний процент жира в молоке за лактацию коров холмогорских помесей был следующим: 3,4; 3,6; 3,2; 3,1; 2,9; 3,7; 3,2; 3,6; 4,0; 3,4; 4,1; 3,8; 3,4; 4,0; 3,3; 3,7; 3,5; 3,6; 3,4; 3,8. Установите доверительные интервалы для генеральной средней при доверительной вероятности 95% (20 баллов).
2. На 400 растениях гибридной ржи первые цветки появились в среднем на 70,5 день после посева. Среднее квадратическое отклонение было 6,9 дня. Определите ошибку средней и доверительные интервалы для генеральной средней и дисперсии при уровне значимости W = 0,05 и W = 0,01 (25 баллов).
3.
При изучении длины листьев 502 экземпляров
садовой земляники были получены следующие
данные:
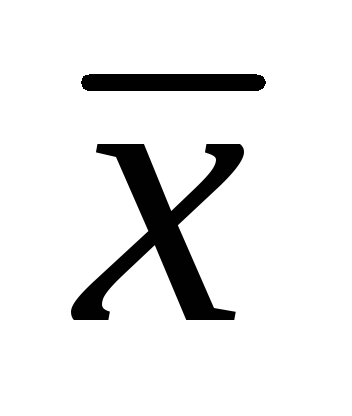 = 7,86 см; σ
= 1,32 см,
= 7,86 см; σ
= 1,32 см,
 =± 0,06 см.
Определите доверительные интервалы
для средней арифметической генеральной
совокупности с уровнями значимости
0,01; 0,02; 0,05. (25 баллов).
=± 0,06 см.
Определите доверительные интервалы
для средней арифметической генеральной
совокупности с уровнями значимости
0,01; 0,02; 0,05. (25 баллов).
4. При обследовании 150 взрослых мужчин средний рост был равен 167 см, а σ = 6 см. В каких пределах находится генеральная средняя и генеральная дисперсия с доверительной вероятностью 0,99 и 0,95? (25 баллов).
5.
Распределение кальция в сыворотке крови
обезьян характеризуется следующими
выборочными показателями:
 = 11,94 мг%, σ
= 1,27, n
= 100. Постройте
95%-ный доверительный интервал для
генеральной средней этого распределения.
Рассчитайте коэффициент вариации (25
баллов).
= 11,94 мг%, σ
= 1,27, n
= 100. Постройте
95%-ный доверительный интервал для
генеральной средней этого распределения.
Рассчитайте коэффициент вариации (25
баллов).
6. Было изучено общее содержание азота в плазме крови крыс-альбиносов в возрасте 37 и 180 дней. Результаты выражены в граммах на 100 см 3 плазмы. В возрасте 37 дней 9 крыс имели: 0,98; 0,83; 0,99; 0,86; 0,90; 0,81; 0,94; 0,92; 0,87. В возрасте 180 дней 8 крыс имели: 1,20; 1,18; 1,33; 1,21; 1,20; 1,07; 1,13; 1,12. Установите доверительные интервалы для разницы с доверительной вероятностью 0,95 (50 баллов).
7. Определите границы 95%-ного доверительного интервала для генеральной дисперсии распределения кальция (мг%) в сыворотке крови обезьян, если для этого распределения объем выборки n = 100, статистическая ошибка выборочной дисперсии s σ 2 = 1,60 (40 баллов).
8. Определите границы 95%-ного доверительного интервала для генеральной дисперсии распределения 40 колосков пшеницы по длине (σ 2 = 40, 87 мм 2). (25 баллов).
9. Курение считают основным фактором, предрасполагающим к обструктивным заболеваниям легких. Пассивное курение таким фактором не считается. Ученые усомнились в безвредности пассивного курения и исследовали проходимость дыхательных путей у некурящих, пассивных и активных курильщиков. Для характеристики состояния дыхательных путей взяли один из показателей функции внешнего дыхания – максимальную объемную скорость середины выдоха. Уменьшение этого показателя – признак нарушения проходимости дыхательных путей. Данные обследования приведены в таблице.
|
Число обследованных |
Максимальная объемная скорость середины выдоха, л/с |
||
|
Стандартное отклонение |
|||
|
Некурящие |
|||
|
работают в помещении, где не курят | |||
|
работают в накуренном помещении | |||
|
Курящие |
|||
|
выкуривающие небольшое число сигарет | |||
|
выкуривающие среднее число сигарет | |||
|
выкуривающие большое число сигарет | |||
По данным таблицы найдите 95% доверительные интервалы для генеральной средней и генеральной дисперсии для каждой из групп. В чем заключаются различия между группами? Результаты представьте графически (25 баллов).
10. Определите границы 95%-ного и 99%-ного доверительного интервала для генеральной дисперсии численности поросят в 64 опоросах, если статистическая ошибка выборочной дисперсии s σ 2 = 8, 25 (30 баллов).
11. Известно, что средняя масса кроликов составляет 2,1 кг. Определите границы 95%-ного и 99%-ного доверительного интервала для генеральной средней и дисперсии при n = 30, σ = 0,56 кг (25 баллов).
12.
У 100 колосьев измеряли озерненность
колоса (Х
),
длину колоса (Y
)
и массу зерна в колосе (Z
).
Найти доверительные интервалы для
генеральной средней и дисперсии при P
1
= 0,95, P
2
= 0,99, P
3
= 0,999, если
 = 19,
= 6,766 см,
= 0,554 г; σ
x 2
= 29, 153, σ
y 2
= 2, 111, σ
z 2
= 0, 064. (25 баллов).
= 19,
= 6,766 см,
= 0,554 г; σ
x 2
= 29, 153, σ
y 2
= 2, 111, σ
z 2
= 0, 064. (25 баллов).
13.
В отобранных случайным образом 100
колосьях озимой пшеницы подсчитывалось
число колосков. Выборочная совокупность
характеризовалась следующими показателями:
 = 15 колосков и σ
= 2,28 шт. Определите, с какой точностью
получен средний результат (
= 15 колосков и σ
= 2,28 шт. Определите, с какой точностью
получен средний результат ( )
и постройте доверительный интервал для
генеральной средней и дисперсии при
95% и 99% уровнях значимости (30 баллов).
)
и постройте доверительный интервал для
генеральной средней и дисперсии при
95% и 99% уровнях значимости (30 баллов).
14. Число ребер на раковинах ископаемого моллюска Orthambonites calligramma :
Известно, что n = 19, σ = 4,25. Определите границы доверительного интервала для генеральной средней и генеральной дисперсии при уровне значимости W = 0,01 (25 баллов).
15. Для определения удоев молока на молочно-товарной ферме ежедневно определялась продуктивность 15 коров. По данным за год каждая корова давала в среднем в сутки следующее количество молока (л): 22; 19; 25; 20; 27; 17; 30; 21; 18; 24; 26; 23; 25; 20; 24. Постройте доверительные интервалы для генеральной дисперсии и средней арифметической. Можно ли ожидать, что среднегодовой удой на каждую корову составит 10000 литров? (50 баллов).
16. С целью определения урожая пшеницы в среднем по агрохозяйству были проведены укосы на пробных участках площадью 1, 3, 2, 5, 2, 6, 1, 3, 2, 11 и 2 га. Урожайность (ц/га) с участков составила 39,4; 38; 35,8; 40; 35; 42,7; 39,3; 41,6; 33; 42; 29 соответственно. Постройте доверительные интервалы для генеральных дисперсии и средней арифметической. Можно ли ожидать, что в среднем по агрохозяйству урожай составит 42 ц/га? (50 баллов).